Introduction
Back in the days when I was a CEO of a Macintosh software publishing company, I designed a powerful text analysis product for the Macintosh platform. When the company closed in 1990, the program disappeared from public view, but to this day, has features that I have found in no other free or low-priced program. For that reason, I am looking for an open source programmer, interested in updating the design elements into a new program, usable on all platforms, and incorporating more modern elements, not available at that time.
The following presents a good overview of the design components all of which the new program should contain.
Import and Split
The first step in using ArchiText is to import the corpus of one or more documents into the program. In the example shown below the text of the 9/11 Commission Report is going to be subjected to analysis.
In general, if the document is of any significant length you'll want to split it into categories or sections which represent some logical division of the whole. After creating a new ArchiText file, select the file you're going to use.
 You can elect to import the entire file, or to split the file into elements, referred to as “Nodes.” If you choose the former, you will have just one node, having the document name.
You can elect to import the entire file, or to split the file into elements, referred to as “Nodes.” If you choose the former, you will have just one node, having the document name.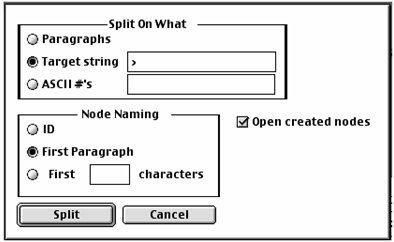
If you decide to split into sections, you can use any symbolic character (or combination of symbolic characters) as the target string by which sections are split, as shown above.
In this example, we have split the entire document into chapters, as illustrated in the Node Directory shown below. Double clicking on any of the Nodes will open a window in which the text of the node appears.
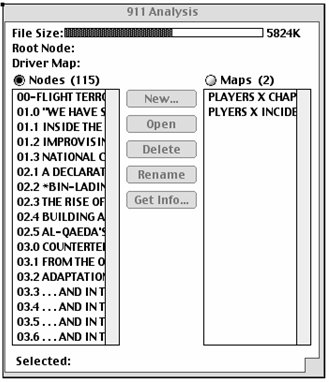 Node Selection
Node SelectionRegardless of the analysis you are going to perform, you can select all nodes, an ordered set of nodes, or a discontinuous combination of nodes. Preferences allow you to order nodes alphabetically or by time modified.
Keyword Lists
Typically this is the first analysis you are going to do. Ordinarily, you will have done a lot of tag preparation in the original file, which are referenced to as we go through the analyses, but the specific methodology will be beyond the scope of this introduction to ArchiText.
In the selection above, our interest was in identifying the key terrorist players, so the keyword search was restricted to those nodes where they were discussed.
After selecting the nodes whose words are to be listed, the keyword dialog sets up the parameters for the listing.

Most of these choices are self-explanatory, but the “stop word list” requires some discussion. ArchiText comes pre-loaded with a modifiable list of words – articles, prepositions and auxiliary verbs, which ordinarily are irrelevant to content. Thus, when this item is checked, these words are eliminated from the frequency listings. However, there are times when these words have usefulness for a given analysis, and they can then be included by unchecking this box.
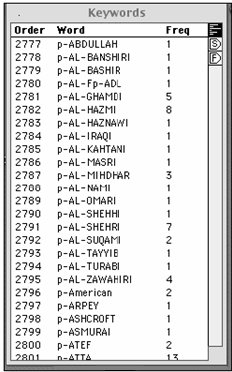
In this partial view of the resulting frequency list, each person has been prefixed by “p-“ which facilitates grouping all of the those named fitting into the category “Person.” For those occurring with high frequency, we will proceed to extract all information regarding them, and combine that information into a single new node only focused on each of them.
Extract and Combine to make new nodes
In our first search, two of the terrorists have been selected. Selecting the “S” tab will automatically initiate the search dialog. Remember that the nodes have been preselected when the keyword list was constructed.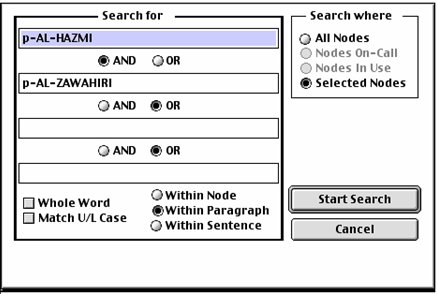
After pressing “Start Search” button, you will see the following results in the Directory.

Notice that the number of occurrences of the names of the two terrorists, within each node, are highlighted. The next step is to extract just this information, and combine it into a new node. To do this, select “Combine Nodes” from the “Analysis” menu.

In the example shown below, we have searched for George Bush, and are extracting all occurrences of his name throughout the nodes.
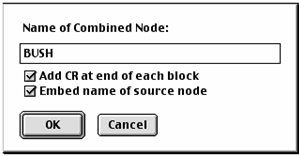
Select “Embed Node Name” if you want the source nodes named in the new node. After completion, a new node containing only those instances in which Bush is named in a paragraph. The result of this combination looks like this:

This illustration is, of course, only a small potion of the nodes in which the Bush Name occurs. If you wish, you can “drill down” further, building a keyword list for this node alone, and searching for other combinations related to Bush, as they occur within Paragraphs or sentences in which his name occurs. If desired, you could build extracted nodes for any combinations of Bush and other words included in your search.
Identify Relationships – Node Maps
In a 500 page document there are obviously a huge number of relationships between people, events, locations, and other categories. Node Maps facilitate your finding and manipulating these relationships in an infinite number of ways.
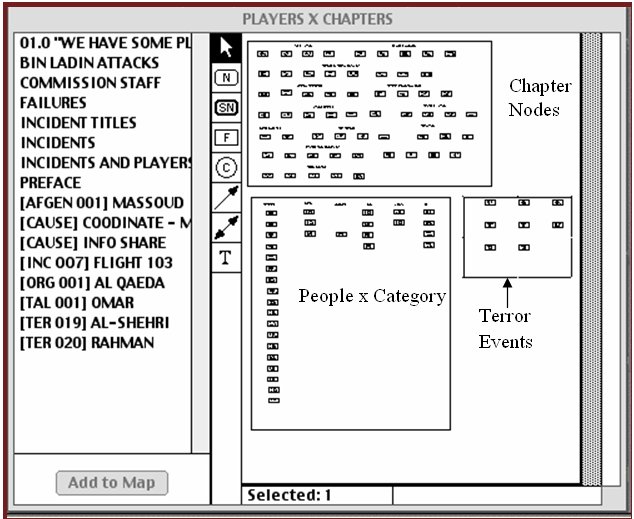
New maps are built in the same way as are new nodes -- by using the create button for maps in the directory dialog. You will note that there are number of nodes which are not on the map, but which are available through selection and pressing the "Add to Map" button. When nodes are deleted from the map, they appear in the left column which is the "On-Call" list. Another way that nodes can be added from the On-Call list is through a search which selects some of the nodes in this list.
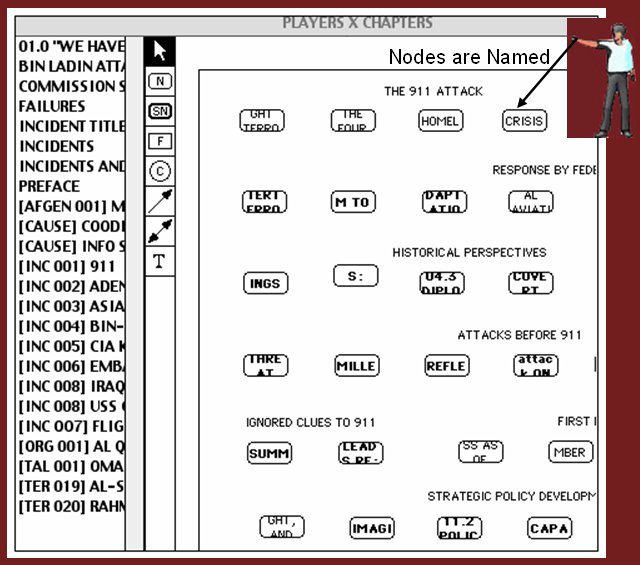
One way of visualizing the nodes found in a search is to change the size of the nodes selected by that search. This option is available by selecting, "Change Node Size," in the Map menu found on the main tool bar.

A far more powerful option is available. Using one all of the eight linking tools which are available a "Parent Node" can be connected or linked to each of the nodes to which a relationship exists. One example of this linking is shown in the map below. In this case, Terrorist 001 (Osama bin Laden) is linked to each of the chapters in which his name appears.
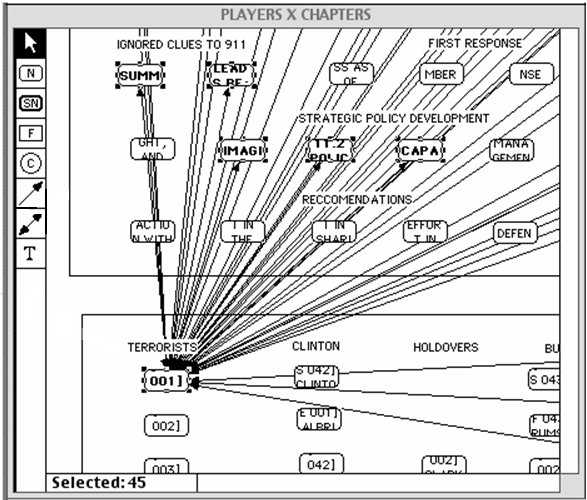
As you see below every node which is linked to another is illustrated in the nodes window. Double clicking on any node name opens the note window, and depending on the preference settings, will either open the source node and destination node, or simultaneously open the destination node while closing the source node.

Implications for data mining
The methodology employed here facilitates the discovery of all kinds of relationships between people, events, locations, and in fact anywhere or phrase to any other. Typically as relationships are discovered new sub nodes will be created so that those relationships can be examined and further linked to other relationships.
It is not necessary to do this specialized tagging which will be explained in the following tutorial directed at methods of text analysis. This simply makes it easier to define categories of items making their location and identification easier within ArchiText and providing a basis for quantitative analyses which can flow from these categorical classifications.
Some limitations
While the design of this program offers features which this author has found in no other program, because it was designed in 1988, there are some limitations and deficiencies which demand starting from the beginning and rebuilding the program shell. Listed below are some of the current problems which must be resolved for the program to reach its potential power for its users:
· By far the most serious deficiency in this program is the fact that it will only operate on older Macintosh computers still installed with OS 9x or below. The search and linking functions are available on no other program, except those enterprise-level highly expensive data mining systems. Thus the program needs to be updated such that is usable on any platform.
· As currently constituted the program only can import text in ASCII format, and lacks the capability to open Internet files or read from them.
· There are number of deficiencies in the search algorithm, most particularly in the program's inability to process numerical searches. Thus, a search for a number greater than, equal to, or less than another quantity can not be accomplished currently.
· As displayed above, they the mapping capabilities of the program are very limited and a number of modifications should be made so that more effective pictographic displays are readily available. An example of one such possibility is shown below.


No comments:
Post a Comment